

Mutation Testing in C#
(This article was first published in Xpirit Magazin #14)
The problem
Let’s face it, software development is hard. It’s a highly creative task that fully takes place in “non-physical worlds” like our mind and inside IT devices. As physical human beings, we live in the real world, we experience the real world, we breathe and speak the real world. The direct consequence is that we learn from all the tiny things that might happen. We know to be cautious with a fresh cup of coffee, based on past experiences, as it might be quite hot.
With software this is a bit different. Sure, we also gain experience over time. We learn to anticipate situations and re-use knowledge from the past, but we cannot easily transfer previous “real world knowledge” to our profession. This is a major difference to other jobs like carpentry or painting, where our human real-world judgement can be applied a bit easier. I mean, you don’t have to be an experienced carpenter to verify if a chair does its job of carrying a human being.
Testing or verifying software on the other hand adds yet another complexity level to our construct in the non-physical world. If your primary code is already quite complex, how do we keep our unit tests simple? Refactoring our primary code becomes easy with a good set of unit tests, granted. But how can we refactor our unit tests? Are we sure that, after a refactoring, our tests yield the same level of confidence / security? Can we be sure that our tests always evolve with the primary code? Maybe, just by accident, a few small bugfixes in the past were made without a companion unit test. Who knows?
Measuring quality
So how do we evaluate the quality of our unit tests? Sure, simple gut feeling would be easy but also highly subjective and nothing we could add to our CI pipeline. Gathering some code coverage metrics while running our unit tests is, on the other hand, something we could easily add to our CI pipeline and would give us some objective numbers. But how do we interpret those numbers?
Coverage metrics only tell you what percentage of your code has been executed. Not what percentage of the business logic behind those lines of code have been evaluated!
And in combination with coverage metrics, you quickly hear or read some guidance like “70% coverage is enough, as 100% is not worth the effort”. Why shouldn’t we strive for 100%? Why do we have to be careful when interpreting those numbers?
Aren’t there better metrics available? Maybe something with a high developer experience that focuses on actionable things instead of theoretical values? We developers like to improve things and not argue about numbers!
Mutation testing to the rescue
Usually, we use unit tests to evaluate our primary code, but with Mutation Testing we turn things upside down! We mutate our primary code to actively break or invert the existing behavior and test if our unit tests are able detect this breaking change. If the unit tests pass, then we know that the original behavior was not properly covered by a test, and we need to rework / sharpen our tests in this regard.
This has the significant benefit of being very hands-on. Because the output of a Mutation Testing run is always “when I break this part of your primary code, no unit tests complain!”. No abstract number to interpret. No softening “70% is good enough”. Mutation Testing can either find places where you have gaps in your unit tests or not. It’s as simple as that.
How do we utilize this in C#?
Stryker.NET is here to help
To make things more concrete let’s start with a short piece of code:
1public class Calculator
2{
3 public int Multiply(int a, int b)
4 {
5 return a * b;
6 }
7}
Yes, this is a very simple class and truly made up for this article. This piece of code is here just to convey the idea and usage of Stryker.NET1 and Mutation Testing in general. Even in this scenario, we try to be good developers who care about quality. Therefor we also have a corresponding unit test that looks like this:
1[TestCase(1, 1, 1)]
2public void Multiply_test(int a, int b, int c)
3{
4 var calc = new Calculator();
5
6 var actual = calc.Multiply(a, b);
7
8 Assert.AreEqual(c, actual);
9}
Here we have a simple piece of code and a unit test that executes it. Our unit test is green, so everything is fine, right? If we would apply our code coverage metric from before, we would be at 100%! Great.
Let’s see what Stryker.NET thinks about our project. For that we quickly need to install the dotnet-stryker command line tool via:
1$ dotnet tool install -g dotnet-stryker
As you can see, Stryker.NET is a simple NuGet package that can be installed globally on your machine (like we just did) or project locally. Which way you prefer is, in the end, a matter of test and/or project convention. Once installed we can execute Stryker.NET against our code and see the results:
1$ cd path/to/your/solution/folder
2$ dotnet stryker
You didn't expect it to be that simple, did you? Stryker.NET tries its best to maintain a high-quality developer experience and will handle as much as possible. There are multiple command-line options available to change the default behavior, such as filtering mutations to a subset of your files, changing the output level, selecting the type of reports to generate, and much more. But for now, we can leave it at the defaults and open the HTML-based report, which is generated by default:
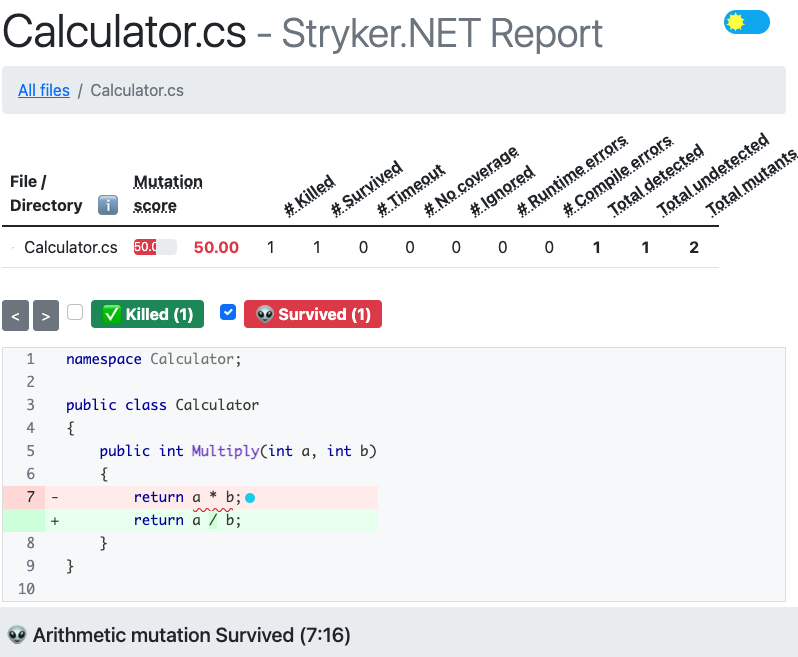
Here we can see that Stryker.NET mutated our original code by replacing the multiplication with a division and our unit tests were still green! Or in Stryker.NET words: the generated mutant was able to survive (no failing unit tests that caught him).
This is true, as our unit test only tested with a limited parameter set! We can do the mutation ourselves, totally invert the business logic and our test does not guard us. Improving our unit test is as simple as adding another parameter variant:
1[TestCase(1, 1, 1)]
2[TestCase(4, 2, 8)] // <-- Additional case
3public void Multiply_test(int a, int b, int c)
4{
5 var calc = new Calculator();
6
7 var actual = calc.Multiply(a, b);
8
9 Assert.AreEqual(c, actual);
10}
In the next round of dotnet stryker this mutant would no longer survive, and we actively improved the quality of our test!
Things that Styker.NET mutates
We saw that Stryker.NET was able to mutate our multiplication with a division and the question is now: What else can Stryker.NET mutate? Because in the end, the amount and diversity of those mutations define the spectrum and quality of the generated mutants.
The good news here: The number of available mutations in Stryker.NET is staggering and spans multiply categories:
| Category | Original | Mutated |
|---|---|---|
| Arithmetic operators | + | - |
| Equality operators | != | == |
| Logical operators | and | or |
| Boolean literals | true | false |
| Assignment statements | += | -= |
| Initializers | new int[] { 1, 2 } | new int[] {} |
| Unary operators | -var | +var |
| Update operators | var++ | var-- |
| LINQ methods | First() | Last() |
| String operators | "foo" | "" |
| Bitwise operators | << | >> |
| Math operators | Floor() | Ceiling() |
| Null-coalescing operators | a ?? b | b |
| Regex operators | abc{5,} | abc{4,} |
| Removal mutators | break | (simply removed) |
As you can see, the list is huge! And I picked only one example out of every category. For a full list of all supported mutations, you should look at the documentation, which is very detailed. If you have any questions, the documentation always has you covered - not only for a list of all mutations.
Mutation score as KPI (Key Performance Indicator)
Stryker.NET will create mutants and count how many of them managed to escape or were caught by our tests. This information can be condensed down to a single score: The mutation score.
The calculation is simple, as we just divide the number of caught mutants by the total amount we created. Given we have created 120 mutants and only 5 of them survived, we get a mutation score of 92% (the higher the better).
This simple score is also visible in the various reporting formats that Stryker.NET can generate. In the default HTML report that we used earlier, we can use this as an uncomplicated guide to find classes that have more escaping mutants and thus less effective unit tests.
Conclusion
Mutation testing turns the world upside down and uses the primary code to evaluate the quality / completeness / robustness of our unit tests. It does so by spawning an army of mutants (logically inverted variants of our primary code), which must be caught by our existing unit tests. Every mutant that escapes (does not trigger a failing unit test) highlights a piece of logic within our primary code that does not have a verifying unit test.
In the end, this methodology is, as a software developer, very hands-on and creates actionable insights. If at some point Stryker.NET is no longer able to create mutants that survive our unit tests, chances are high that future-me can also not accidentally create mutants in the next refactoring. And this is what I really care about: Trustworthy unit tests.